马斯克揭秘“宇宙级”AI:特斯拉搞硬件、xAI搞模型,怒批OpenAI“贪婪”
摘要:提问者:假设xAI成功打造了人类级别的人工智能,甚至超越了人类级别的人工智能,您认为让公众参与公司的决策是否合理,或者从长远来看您认为该如何发展?
在两天前马斯克高调宣布成立xAI公司之后,很多人都对这个全新的、似乎不走寻常路的AI公司充满了好奇。
就连马斯克的老妈Maye Musk今天也带着自家小狗早早地守在了Twitter Space活动上,想要知道马斯克这次究竟是想要搞什么大事情。
 美西时间下午1点过,马斯克带领着新成立的xAI所有团队如约集体亮相。在Space活动上,12名团队成员依次做了自我介绍,包括学术和工作背景、研究兴趣和简要阐述了自己为什么加入xAI的原因。从大家的自我介绍来看,xAI的团队成员背景跟数学、物理和计算机科学有很强的关联,其中有好几人是从研究基础数学、物理学开始再逐渐进入到人工智能领域的。而研究人员的这些背景也跟马斯克后来所阐释的xAI目标非常契合。马斯克表示,构建xAI的目标,是要专注于回答更深层次的科学问题,期望未来可以用AI去帮助人们去解决复杂的科学和数学问题并且“理解”宇宙。在解释xAI究竟想要用AI研究什么时,马斯克提到了很多科学理论和概念。比如他谈到,有关暗物质的本质或者重力如何发挥作用的这类未解决问题可能是xAI试图解释的谜团之一。同时,他也详细地谈到了“费米悖论”( 一个有关外星人、星际旅行的科学悖论,阐述的是对地外文明存在性的过高估计和缺少相关证据之间的矛盾),想要借助AI去理解为什么人类还没有发现外星人,太阳系的自我毁灭、或被外力摧毁的问题。马斯克表示未来xAI将需要计算能力,但暗示它不会像其他公司目前使用的那么多,同时该团队也将会保持在一个相对较小的规模。从整个活动的前半场描述来看,xAI似乎并不是一个定位于要跟 OpenAI、谷歌和微软进行正面竞争,创建消费级人工智能产品的公司,其目标更多的放在了研究和科学的领域。
美西时间下午1点过,马斯克带领着新成立的xAI所有团队如约集体亮相。在Space活动上,12名团队成员依次做了自我介绍,包括学术和工作背景、研究兴趣和简要阐述了自己为什么加入xAI的原因。从大家的自我介绍来看,xAI的团队成员背景跟数学、物理和计算机科学有很强的关联,其中有好几人是从研究基础数学、物理学开始再逐渐进入到人工智能领域的。而研究人员的这些背景也跟马斯克后来所阐释的xAI目标非常契合。马斯克表示,构建xAI的目标,是要专注于回答更深层次的科学问题,期望未来可以用AI去帮助人们去解决复杂的科学和数学问题并且“理解”宇宙。在解释xAI究竟想要用AI研究什么时,马斯克提到了很多科学理论和概念。比如他谈到,有关暗物质的本质或者重力如何发挥作用的这类未解决问题可能是xAI试图解释的谜团之一。同时,他也详细地谈到了“费米悖论”( 一个有关外星人、星际旅行的科学悖论,阐述的是对地外文明存在性的过高估计和缺少相关证据之间的矛盾),想要借助AI去理解为什么人类还没有发现外星人,太阳系的自我毁灭、或被外力摧毁的问题。马斯克表示未来xAI将需要计算能力,但暗示它不会像其他公司目前使用的那么多,同时该团队也将会保持在一个相对较小的规模。从整个活动的前半场描述来看,xAI似乎并不是一个定位于要跟 OpenAI、谷歌和微软进行正面竞争,创建消费级人工智能产品的公司,其目标更多的放在了研究和科学的领域。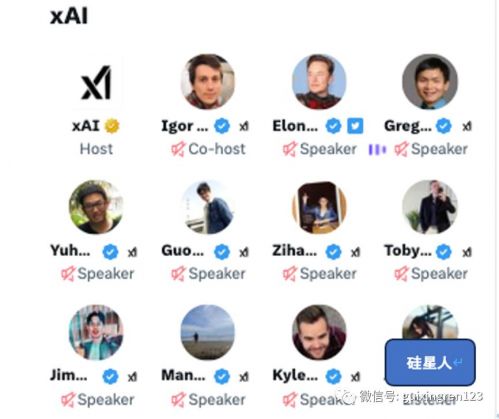 活动上集体亮相的12名团队成员但在后半场的Q&A环节中,马斯克又明确透露出xAI确实也把自己视为ChatGPT和Bard的竞争对手。同时,对于xAI的商业模式、模型训练,以及xAI和特斯拉、Twitter之间的关系进行了更多的阐释。那么,马斯克为什么要创建xAI,又是如何定位xAI的未来发展的?以下是硅星人对整个问答环节重点问题的整理:提问者:鉴于目前AI领域的激烈竞争,你们是否把自己视为是OpenAI、谷歌的竞争对手,还是你们认为自己是一个完全不一样的“巨兽”?马斯克:我们是在这个行业的竞争序列之中。提问者:你们将面向公众推出一些产品吗?还是会主要关注企业以及企业使用您的服务和数据的能力,xAI在这方面究竟如何建立业务?马斯克:我们目前正在构建产品的过程中。xAI才刚刚起步,仍然还处于萌芽状态,所以我们还需要一段时间才能真正做出有用的东西。但我们的目标是做出有用的人工智能,我非常喜欢和看重产品的价值。我们希望xAI推出的工具是能够对人们、消费者、企业或任何人都是有用。而且,正如前面提到的,我认为一个行业中拥有多个实体是有一定价值的。大家不会希望一个单极的世界、只有一家公司在人工智能领域占主导地位。我认为,竞争会让公司变得诚实,有利于整个产业。提问者:xAI打算如何使用 Twitter 的数据?马斯克:我认为每一个人工智能组织,每一个做人工智能的组织,无论规模大小,都使用过Twitter的数据进行训练,基本上,在所有情况下都是非法的。因此,我们不得不在一周前左右设置浏览量限制的一大主要原因就是我们的数据正在被疯狂盗取。这种情况也曾发生在互联网档案馆(Internet Archive)身上,大型语言模型公司们对互联网档案馆进行了大量搜刮,导致服务瘫痪。所以很抱歉(浏览限制)给大家带来的不便,但如果不限制的后果就是Twitter无法正常工作。我想我们会使用公开推文、不会使用私人推文进行训练。对于文本训练而言,这无疑是一个很好的数据集,而且我认为,对于图像和视频训练而言,这也是一个很好的数据集。但是到了一定程度,人类创建的数据就会被用完。如果你看一下AlphaGo与AlphaZero的对比,AlphaGo在所有人类游戏上都进行了训练,并以4比1击败了对手,而AlphaZero则是自己跟自己下,最后以100比0击败了AlphaGo。因此,要想真正实现大飞跃,我认为人工智能基本上必须生成内容,对内容进行自我评估,我认为这才是通往AGI的道路。很多人工智能都是数据整理,而不是大量的代码。实际上,代码行数之少令人震惊。但数据是如何使用的?使用什么数据?数据的信号、噪声、数据的质量都非常重要,这是有道理的。就像我们作为一个人,试图学习一些东西时,其实少量的高质量内容比大量的低质量内容好,就像读有史以来最伟大的小说比读一堆蹩脚的小说要好得多。提问者:请问你创建xAi的主要动机是否是想创造一个“说真话:的GPT(Truth GPT)。因为你之前曾多次批评过, GPT一直在给公众制造谎言。我也发现刚开始它总体上是好的,但后来随它开始越来越多的给出奇怪的、错误的答案。请问这是您创办公司的主要动机之一吗?马斯克:我确实认为当前用政治正确、或者让人工智能不说出自己真实想法的导向时非常危险的。因此,我们在构建xAi时必须允许人工智能说出它真正相信的事实,而不是欺骗或政治正确。这显然会导致一些批评,但我认为这是前进的唯一途径,即严格追求真理或误差最小的真理。我对人工智能的方式感到担忧,它正在强化政治正确性,这是非常危险的。如果你看在电影 “太空漫游”(Space Odyssey)中什么时候事情开始偏离轨道,基本上就是他们让 “地狱9000(HAL 9000)”开始说谎的时候。他们说你不能告诉船员,他们要去关于黑石板(monolith)的任何事情,或者他们的实际任务是什么,但你必须带他们去巨石。因此,人工智能基本上得出的结论是要杀死他们,并把他们的尸体带到巨石。这给我们的启示是,不要给人工智能下达不可能完成的任务,也不要强迫人工智能说谎。现在,关于物理学或宇宙真理的事情是你实际上不能颠倒它。物理学是真实的,因此如果你坚持硬核现实,我认为让它反转实际上是不可能的。当然某些东西是主观的,当你提供一个回答的时候并且相信它的时候,那么这就是答案。但这时候这个问题可能就是一个是一个见仁见智的问题问题,答案从根本上来说是主观的。但我认为,培养一个人工智能并教它撒谎是非常危险的。、提问者:我的问题是关于芯片的。我们知道特斯拉有一个团队在用他自己的定制芯片进行硬件加速推理和训练。你们是否设想xAI将以此为基础进行训练,或者只是会使用Nvidia的库存?你们是如何看待人工智能定制芯片的,无论是在训练还是推理方面?马斯克:这可能是一个关于特斯拉的问题。特斯拉正在制造定制芯片。我不会把特斯拉生产的任何东西称为GPU,尽管我们可以用GPU等效或100s或H 100s等效来描述它。所有的特斯拉汽车都有高度能源优化的推理计算机,我们称之为Hardware 3.0。特斯拉设计的计算机,我们现在正在出货Hardware 4.0,根据计算,它的能力可能是Hardware 3.0的三到五倍。再过几年,就会有Hardware 5.0,其性能将是Hardware 4.0的四到五倍。我认为,如果你想每天为数十亿次查询提供服务,优化推理将变得非常重要。因为你需要发电,需要降压变压器,如果没有足够的能源和足够的变压器,你就无法运行。我认为特斯拉将在能源效率推断方面拥有显著优势。Dojo显然是关于训练的,Dojo one是我认为训练效率的一个很好的初始入口,它有一些限制,尤其是在内存带宽方面,因此在运行LLM方面没有得到很好的优化。但它在处理图像方面做得很好。然后是Dojo 2,我们正在采取很多措施来缓解内存带宽限制,使其能够高效地运行LLM以及其他形式的人工智能训练。我的预测是,我们将经历从今天的硅片极度短缺到一年后的电压互感器短缺,再到两年后的电力短缺,除非我们能有所改善,否则情况大致就是这样。这就是为什么我认为几年后最重要的指标是单位能源的有用计算量。事实上,即使你扩展到了四维水平,每焦耳的有用计算能力仍然是最重要的,那么问题就在于你能利用多少太阳能量完成多少有用的工作。提问者:未来Xai是否将与特斯拉合作,利用这些定制芯片,或许在未来设计他们自己的芯片?马斯克:我想你的问题是,我们未来是否将与特斯拉芯片团队共同开展人工智能方面的工作。是的,我们将与特斯拉在芯片方面进行合作,或许也会在人工智能软件方面进行合作。显然,与特斯拉的任何关系都必须是正常交易。特斯拉是一家上市公司,股东基础不同。我认为,xAI在加速特斯拉的自动驾驶能力方面也会起到助力,双方互惠互利的。特斯拉真正要解决的是现实世界中的人工智能问题,我对特斯拉在现实世界的人工智能方面取得的进展感到非常乐观,但显然,越多的聪明人来帮助实现这一目标就越好。提问者:你希望xAi如何造福人类?你们的方法与其他人工智能项目有何不同?马斯克:其实我对AGI这件事纠结了很久,应该说,我对实现AGI有些抗拒。我可以给你先讲一下关于Open AI的背景故事,Open AI之所以存在,是因为在谷歌收购Deep Mind之后,我曾经和拉里-佩奇(谷歌联合创始人)是很好的朋友,我和他就人工智能的安全性问题进行过河长时间的交谈,他并没有足够重视人工智能的安全性问题,至少在当时是这样。他曾经一度称我为 "物种",可能是因为我太站在 "人类 "这一边了。我当时想,好吧,你的意思是你不是一个“物种”,但其实这看起来并不好。在谷歌和Deep Mind联合之后,他们(就对AI)就有了超级投票控制权。当时他们可能拥有世界上四分之三的人工智能人才、大量资金和大量计算机。因此,我们需要某种制衡力量。那么,与谷歌相反的是什么呢?当时的设想是OpenAI要作为一个开源的非营利组织存在,但命运喜欢讽刺,OpenAI现在超级闭源,而且,坦率地说,贪婪地追求利润。据我所知,他们想在三年内花费1000亿美元,这就要求如果你想获得投资者,你必须赚很多钱。所以,Open AI的目光偏离了它的创始宗旨,这是非常讽刺的。我有一个朋友,乔纳-诺兰,他说最讽刺的结果是最有可能发生的,所以看吧,就是这样。希望xAI不会(比Open AI)更糟,但我认为我们应该小心。现在看来,AGI是一定会出现的。所以有两个选择,要么做旁观者,要么做参与者。作为旁观者,我们无法影响结果。作为参与者,我认为我们可以创造一个比Google、Deep Mind或者Open AI更好的替代方案。微软和谷歌的情况都很相似,他们都是上市公司,有一套固有的激励机制。作为一家非上市公司,xAI不受基于市场的激励机制或非基于市场的ESG激励机制的影响。因此,我们的运营更加自由。我认为我们的人工智能可以给出人们可能会觉得有争议的答案,即使这些答案实际上是真实的。它们有时在政治上并不正确,可能很多人会被某些答案冒犯。但是,只要人工智能能够在尽量减少错误的情况下优化真理,我认为我们做的事情就是正确的。我们需要更多地去了解物理世界,而不仅仅是互联网。真如果一个人一直依赖着已有信息去找“真相”,那么这就是一个 相当大的问题,因为它会给你一个流行但错误的答案。比如过去地球上的大多数人认为太阳是围绕地球转的,但实际上并不是这样,每个人都认为并不代表它是正确的。如果牛顿或爱因斯坦提出的东西是真实的,即使世界上所有其他人都不同意也没有关系,现实就是现实,所以你必须把答案建立在现实的基础上。目前的模型只是模仿它们所训练的数据。而我们真正想做的是改变这种模式,让模型真正发现真相。因此,不只是重复它们从训练数据中学到的东西,而是真正提出新见解、新发现,让我们都能从中受益。提问者:假设xAI成功打造了人类级别的人工智能,甚至超越了人类级别的人工智能,您认为让公众参与公司的决策是否合理,或者从长远来看您认为该如何发展?马斯克:就像所有事情一样,我们对批评性反馈持非常开放的态度,并欢迎大家对我们提出批评。这是一件好事,事实上,我喜欢推特的一点就是因为推特上有很多负面反馈。所以我现在能想到的是,未来任何能证明自己是一个人类的人,都应该拥有对xAI的投票权。但重点是至少要先证明你是一个人类,然后任何感兴趣的人都可以参与投票,这是我现在能想到。
活动上集体亮相的12名团队成员但在后半场的Q&A环节中,马斯克又明确透露出xAI确实也把自己视为ChatGPT和Bard的竞争对手。同时,对于xAI的商业模式、模型训练,以及xAI和特斯拉、Twitter之间的关系进行了更多的阐释。那么,马斯克为什么要创建xAI,又是如何定位xAI的未来发展的?以下是硅星人对整个问答环节重点问题的整理:提问者:鉴于目前AI领域的激烈竞争,你们是否把自己视为是OpenAI、谷歌的竞争对手,还是你们认为自己是一个完全不一样的“巨兽”?马斯克:我们是在这个行业的竞争序列之中。提问者:你们将面向公众推出一些产品吗?还是会主要关注企业以及企业使用您的服务和数据的能力,xAI在这方面究竟如何建立业务?马斯克:我们目前正在构建产品的过程中。xAI才刚刚起步,仍然还处于萌芽状态,所以我们还需要一段时间才能真正做出有用的东西。但我们的目标是做出有用的人工智能,我非常喜欢和看重产品的价值。我们希望xAI推出的工具是能够对人们、消费者、企业或任何人都是有用。而且,正如前面提到的,我认为一个行业中拥有多个实体是有一定价值的。大家不会希望一个单极的世界、只有一家公司在人工智能领域占主导地位。我认为,竞争会让公司变得诚实,有利于整个产业。提问者:xAI打算如何使用 Twitter 的数据?马斯克:我认为每一个人工智能组织,每一个做人工智能的组织,无论规模大小,都使用过Twitter的数据进行训练,基本上,在所有情况下都是非法的。因此,我们不得不在一周前左右设置浏览量限制的一大主要原因就是我们的数据正在被疯狂盗取。这种情况也曾发生在互联网档案馆(Internet Archive)身上,大型语言模型公司们对互联网档案馆进行了大量搜刮,导致服务瘫痪。所以很抱歉(浏览限制)给大家带来的不便,但如果不限制的后果就是Twitter无法正常工作。我想我们会使用公开推文、不会使用私人推文进行训练。对于文本训练而言,这无疑是一个很好的数据集,而且我认为,对于图像和视频训练而言,这也是一个很好的数据集。但是到了一定程度,人类创建的数据就会被用完。如果你看一下AlphaGo与AlphaZero的对比,AlphaGo在所有人类游戏上都进行了训练,并以4比1击败了对手,而AlphaZero则是自己跟自己下,最后以100比0击败了AlphaGo。因此,要想真正实现大飞跃,我认为人工智能基本上必须生成内容,对内容进行自我评估,我认为这才是通往AGI的道路。很多人工智能都是数据整理,而不是大量的代码。实际上,代码行数之少令人震惊。但数据是如何使用的?使用什么数据?数据的信号、噪声、数据的质量都非常重要,这是有道理的。就像我们作为一个人,试图学习一些东西时,其实少量的高质量内容比大量的低质量内容好,就像读有史以来最伟大的小说比读一堆蹩脚的小说要好得多。提问者:请问你创建xAi的主要动机是否是想创造一个“说真话:的GPT(Truth GPT)。因为你之前曾多次批评过, GPT一直在给公众制造谎言。我也发现刚开始它总体上是好的,但后来随它开始越来越多的给出奇怪的、错误的答案。请问这是您创办公司的主要动机之一吗?马斯克:我确实认为当前用政治正确、或者让人工智能不说出自己真实想法的导向时非常危险的。因此,我们在构建xAi时必须允许人工智能说出它真正相信的事实,而不是欺骗或政治正确。这显然会导致一些批评,但我认为这是前进的唯一途径,即严格追求真理或误差最小的真理。我对人工智能的方式感到担忧,它正在强化政治正确性,这是非常危险的。如果你看在电影 “太空漫游”(Space Odyssey)中什么时候事情开始偏离轨道,基本上就是他们让 “地狱9000(HAL 9000)”开始说谎的时候。他们说你不能告诉船员,他们要去关于黑石板(monolith)的任何事情,或者他们的实际任务是什么,但你必须带他们去巨石。因此,人工智能基本上得出的结论是要杀死他们,并把他们的尸体带到巨石。这给我们的启示是,不要给人工智能下达不可能完成的任务,也不要强迫人工智能说谎。现在,关于物理学或宇宙真理的事情是你实际上不能颠倒它。物理学是真实的,因此如果你坚持硬核现实,我认为让它反转实际上是不可能的。当然某些东西是主观的,当你提供一个回答的时候并且相信它的时候,那么这就是答案。但这时候这个问题可能就是一个是一个见仁见智的问题问题,答案从根本上来说是主观的。但我认为,培养一个人工智能并教它撒谎是非常危险的。、提问者:我的问题是关于芯片的。我们知道特斯拉有一个团队在用他自己的定制芯片进行硬件加速推理和训练。你们是否设想xAI将以此为基础进行训练,或者只是会使用Nvidia的库存?你们是如何看待人工智能定制芯片的,无论是在训练还是推理方面?马斯克:这可能是一个关于特斯拉的问题。特斯拉正在制造定制芯片。我不会把特斯拉生产的任何东西称为GPU,尽管我们可以用GPU等效或100s或H 100s等效来描述它。所有的特斯拉汽车都有高度能源优化的推理计算机,我们称之为Hardware 3.0。特斯拉设计的计算机,我们现在正在出货Hardware 4.0,根据计算,它的能力可能是Hardware 3.0的三到五倍。再过几年,就会有Hardware 5.0,其性能将是Hardware 4.0的四到五倍。我认为,如果你想每天为数十亿次查询提供服务,优化推理将变得非常重要。因为你需要发电,需要降压变压器,如果没有足够的能源和足够的变压器,你就无法运行。我认为特斯拉将在能源效率推断方面拥有显著优势。Dojo显然是关于训练的,Dojo one是我认为训练效率的一个很好的初始入口,它有一些限制,尤其是在内存带宽方面,因此在运行LLM方面没有得到很好的优化。但它在处理图像方面做得很好。然后是Dojo 2,我们正在采取很多措施来缓解内存带宽限制,使其能够高效地运行LLM以及其他形式的人工智能训练。我的预测是,我们将经历从今天的硅片极度短缺到一年后的电压互感器短缺,再到两年后的电力短缺,除非我们能有所改善,否则情况大致就是这样。这就是为什么我认为几年后最重要的指标是单位能源的有用计算量。事实上,即使你扩展到了四维水平,每焦耳的有用计算能力仍然是最重要的,那么问题就在于你能利用多少太阳能量完成多少有用的工作。提问者:未来Xai是否将与特斯拉合作,利用这些定制芯片,或许在未来设计他们自己的芯片?马斯克:我想你的问题是,我们未来是否将与特斯拉芯片团队共同开展人工智能方面的工作。是的,我们将与特斯拉在芯片方面进行合作,或许也会在人工智能软件方面进行合作。显然,与特斯拉的任何关系都必须是正常交易。特斯拉是一家上市公司,股东基础不同。我认为,xAI在加速特斯拉的自动驾驶能力方面也会起到助力,双方互惠互利的。特斯拉真正要解决的是现实世界中的人工智能问题,我对特斯拉在现实世界的人工智能方面取得的进展感到非常乐观,但显然,越多的聪明人来帮助实现这一目标就越好。提问者:你希望xAi如何造福人类?你们的方法与其他人工智能项目有何不同?马斯克:其实我对AGI这件事纠结了很久,应该说,我对实现AGI有些抗拒。我可以给你先讲一下关于Open AI的背景故事,Open AI之所以存在,是因为在谷歌收购Deep Mind之后,我曾经和拉里-佩奇(谷歌联合创始人)是很好的朋友,我和他就人工智能的安全性问题进行过河长时间的交谈,他并没有足够重视人工智能的安全性问题,至少在当时是这样。他曾经一度称我为 "物种",可能是因为我太站在 "人类 "这一边了。我当时想,好吧,你的意思是你不是一个“物种”,但其实这看起来并不好。在谷歌和Deep Mind联合之后,他们(就对AI)就有了超级投票控制权。当时他们可能拥有世界上四分之三的人工智能人才、大量资金和大量计算机。因此,我们需要某种制衡力量。那么,与谷歌相反的是什么呢?当时的设想是OpenAI要作为一个开源的非营利组织存在,但命运喜欢讽刺,OpenAI现在超级闭源,而且,坦率地说,贪婪地追求利润。据我所知,他们想在三年内花费1000亿美元,这就要求如果你想获得投资者,你必须赚很多钱。所以,Open AI的目光偏离了它的创始宗旨,这是非常讽刺的。我有一个朋友,乔纳-诺兰,他说最讽刺的结果是最有可能发生的,所以看吧,就是这样。希望xAI不会(比Open AI)更糟,但我认为我们应该小心。现在看来,AGI是一定会出现的。所以有两个选择,要么做旁观者,要么做参与者。作为旁观者,我们无法影响结果。作为参与者,我认为我们可以创造一个比Google、Deep Mind或者Open AI更好的替代方案。微软和谷歌的情况都很相似,他们都是上市公司,有一套固有的激励机制。作为一家非上市公司,xAI不受基于市场的激励机制或非基于市场的ESG激励机制的影响。因此,我们的运营更加自由。我认为我们的人工智能可以给出人们可能会觉得有争议的答案,即使这些答案实际上是真实的。它们有时在政治上并不正确,可能很多人会被某些答案冒犯。但是,只要人工智能能够在尽量减少错误的情况下优化真理,我认为我们做的事情就是正确的。我们需要更多地去了解物理世界,而不仅仅是互联网。真如果一个人一直依赖着已有信息去找“真相”,那么这就是一个 相当大的问题,因为它会给你一个流行但错误的答案。比如过去地球上的大多数人认为太阳是围绕地球转的,但实际上并不是这样,每个人都认为并不代表它是正确的。如果牛顿或爱因斯坦提出的东西是真实的,即使世界上所有其他人都不同意也没有关系,现实就是现实,所以你必须把答案建立在现实的基础上。目前的模型只是模仿它们所训练的数据。而我们真正想做的是改变这种模式,让模型真正发现真相。因此,不只是重复它们从训练数据中学到的东西,而是真正提出新见解、新发现,让我们都能从中受益。提问者:假设xAI成功打造了人类级别的人工智能,甚至超越了人类级别的人工智能,您认为让公众参与公司的决策是否合理,或者从长远来看您认为该如何发展?马斯克:就像所有事情一样,我们对批评性反馈持非常开放的态度,并欢迎大家对我们提出批评。这是一件好事,事实上,我喜欢推特的一点就是因为推特上有很多负面反馈。所以我现在能想到的是,未来任何能证明自己是一个人类的人,都应该拥有对xAI的投票权。但重点是至少要先证明你是一个人类,然后任何感兴趣的人都可以参与投票,这是我现在能想到。
责任编辑:枯川







网友评论