自治类GPT&工具的调用-上|盖世大学堂汽车大模型应用系列知识讲解
在人工智能的发展历程中,自治类GPT的出现标志着技术的重大突破,其发展过程涵盖多个阶段,每个阶段都伴随着独特的技术演进与挑战。
自治类GPT的发展可追溯到以Langchain为鼻祖的阶段。Langchain为后续的相关技术发展奠定了基础,从开发角度来看,虽然其实现并非特别复杂,但更考验开发者的思维方式。随着技术的发展,如今的代码编写变得愈发简单,开发人员的核心竞争力逐渐从单纯的代码编写能力,转向对业务的熟悉程度。在未来,随着工具的不断成熟,业务人员也有可能具备开发思路,这并非是一方取代另一方,而是双方相互学习、掌握对方认知领域的过程。

在Langchain的基础上,衍生出了众多类似AutoGPT、babyagi、AgentGPT等业务。其中,AutoGPT在2023年发布后,在GitHub上呈现出惊人的上升趋势。它作为一款开源软件,旨在利用大语言模型(LLM)构建工具链体系,实现工作的自动化完成。例如,传统的开发模式是开发者根据老板提出的需求进行开发并产出成果,而在未来,可能是老板提出需求后,由机器人利用相关模型进行开发并得出成果。甚至模型还能基于自身需求,进行如付费购买服务器资源等操作,这体现了整个行业对于人工智能未来发展愿景的一种大胆尝试。尽管目前在工程化实践方面还存在诸多不足,但这种探索具有极高的价值。
以AutoGPT为例,它具备强大的功能,能够调用大量工具,包括搜索引擎、支付宝等,甚至可以发送邮件。然而,其逻辑推理能力相对较弱,导致在推理过程中常常得出不尽人意的结论。在实际应用中,自治类GPT虽然可以实现如支付计算存储费用、组织分解工作、制定计划等功能,甚至能够创建agent并行申请运行和开发资源、收集数据、开发子功能并进行部署,但目前仍无法完全实现自动化。在运行过程中,它们容易陷入死循环,思考过程不够成熟,在编写测试用例、进行集成以及观察最终行为等方面存在诸多问题。
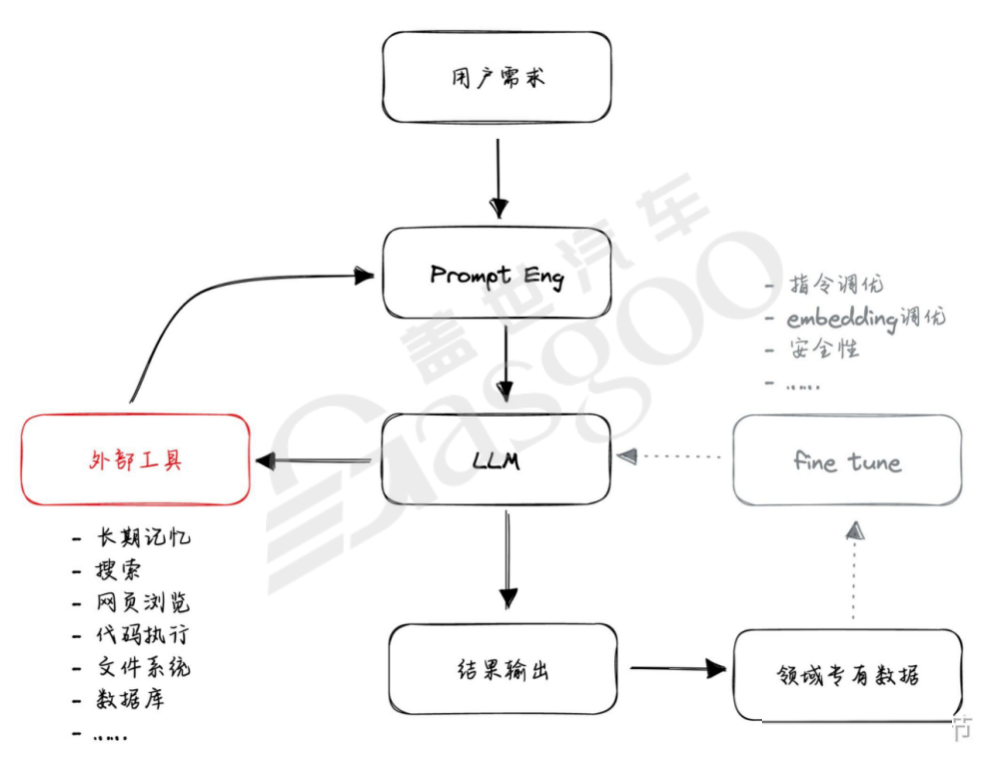
自治类GPT在运行过程中形成了两个核心循环逻辑。其一,通过提示词工程,借助语言模型组织分解任务并调用外部工具,将得到的中间反馈结果融入提示词工程,再次进入语言模型进行迭代,最终确定输出结果。在这个过程中,提示词的编写至关重要,需要明确目标、逻辑限制、角色定义、额外知识以及问题等多方面内容。当涉及调用其他工具时,还需提供资源清单以及相应的输出结构体要求。同时,过往的聊天成果也会作为下一轮输入的一部分,从而形成一个完整的提示词工程循环。其二,当自治类GPT在运行过程中表现不稳定时,可以通过调整LL模型来改善,但这种方式成本较高,相比之下,提示词工程循环更受个人和社区的青睐,因为它对资源的要求相对较低,且实现方式更为人性化,只要具备一定开发基础和广泛认知的人都可以尝试。
尽管自治类GPT具有诸多创新之处,但它在实际应用中仍面临着一系列严峻的问题。在思考稳定性方面,它常常出现简单问题复杂化或复杂问题简单化的情况。例如,面对简单问题时,它可能会按照固定流程进行繁琐的处理;而对于复杂问题,却又无法充分分解任务,仅仅简单地建议查询网页。此外,它还容易陷入思考的死循环,对问题的背景理解不充分,导致从顶层就出现错误判断,进而选择错误的处理范式和工具参数调用,而且在出现错误方向后难以纠正。同时,它无法快速认知自身能力范围,经常调用无法使用的工具,还存在记忆缺失的问题,容易忘记之前的背景信息。在开发与生产关系的区分上,它也表现不佳,无法有效计算多种方案的成本并选择最优方案。
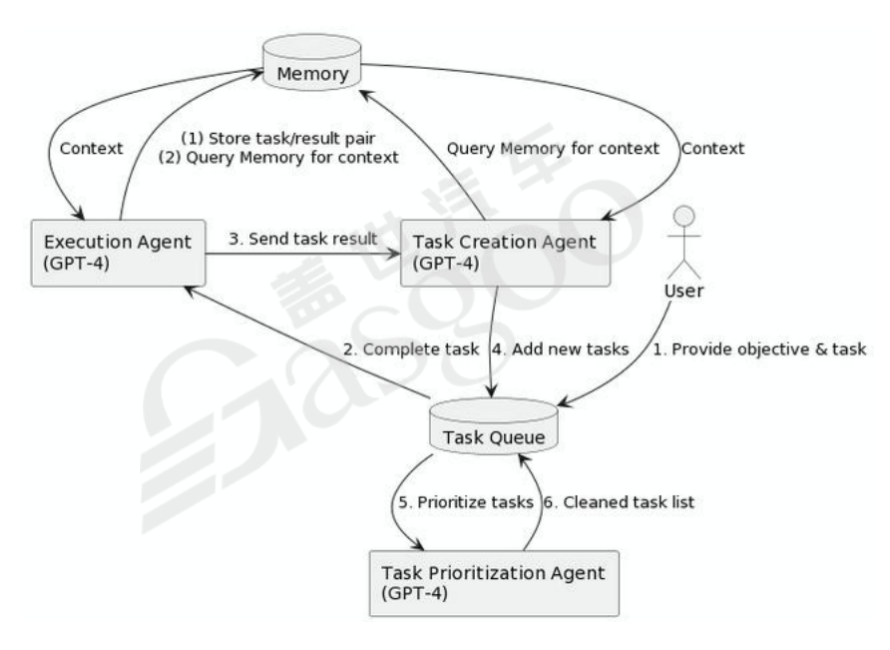
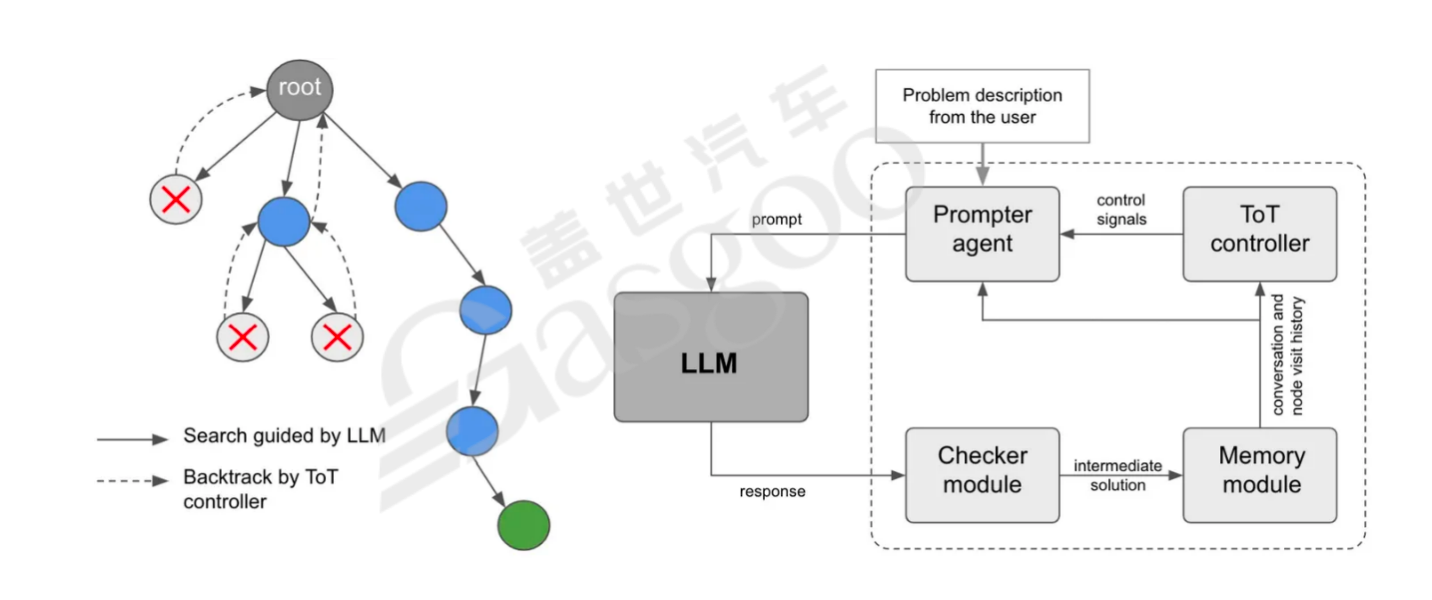
为了解决这些问题,研究人员提出了多种方法论。例如,强化逻辑过程,类似于模拟人类的思考方式,让模型生成固定思维并将任务放入清单循环执行;强化记忆深度,构建深层次的记忆结构,使开发过程能够更好地转化为生产应用;强化规则工具的使用,充分利用人类的知识财富。像babyagi通过合适的Prompt让AI自行分解任务并建立ToDo清单,然后逐项执行任务并生成新任务,不断循环,模拟人类真实的工作流程。还有如ToT(Treeof Thoughts)引入“思想树”推理框架,允许LLMs考虑多个推理路径并进行自我评估选择,以做出全局决策,但这种方式对算力的消耗较大。GoT(Graphof Thoughts)则适用于可自然分解为子任务的任务,通过融合子任务的解答来得到最终结果。
记忆能力的构建也是自治类GPT发展中的关键环节。一方面,可以通过压缩总结聊天记录、结构化记录或分组总结观点等方式,在有限的token限制下增强模型的记忆能力,使其能够更好地利用上下文背景信息。另一方面,衔接外部向量数据库是目前较为成熟的方案。具体做法是将文档切片后转化为token,利用大语言模型生成相关token服务,通过计算问题与文档片段token之间的相似度,搜索最相关的片段并拼接到提示词背景中,从而提高模型回答的可控性和专业性。然而,目前在持久化学习方面,即智能体进行长周期知识积累和知识结构持续集成的能力,仍处于研究阶段,尚未形成成熟的方案。
在工具强化方面,基于LM模型使其成为新的流量入口是商业化的热门方向。将各类软件的API接口整合到语言模型内部,能够为用户提供有价值的服务,例如帮助用户制定旅游计划、进行机票酒店比价等。但这一过程也存在激烈的利益争夺,因为每家公司都拥有自己的数据,都希望在这个领域占据一席之地。目前,将相关技术接入各类终端系统,如飞书、微信等,已经成为常见的应用方式,还可以嵌入到小机器人或专业化软件中,拓展业务功能。
在部署搭建方面,主要存在几种不同的逻辑。商业大模型加插件的方式对普通用户最为友好,投入成本相对较低,但可能面临网络安全等问题;商业专有大模型能够开箱即用,满足一些工程实践任务,但无法很好地串联工作流,且多个功能可能反复收费,成本较高;自购GPU服务器进行部署具有最高的自由度,可以定制端到端(E2E)的工作流,甚至对外提供服务,但开发能力要求高,硬件成本也非常高,部分模型可能无法充分利用其算力;自购CPU服务器并衔接云原生服务具有一定的自由度,可定制E2E工作流,能够对外提供服务,成本相对可控,但在规模化和量产化方面仍存在瓶颈。
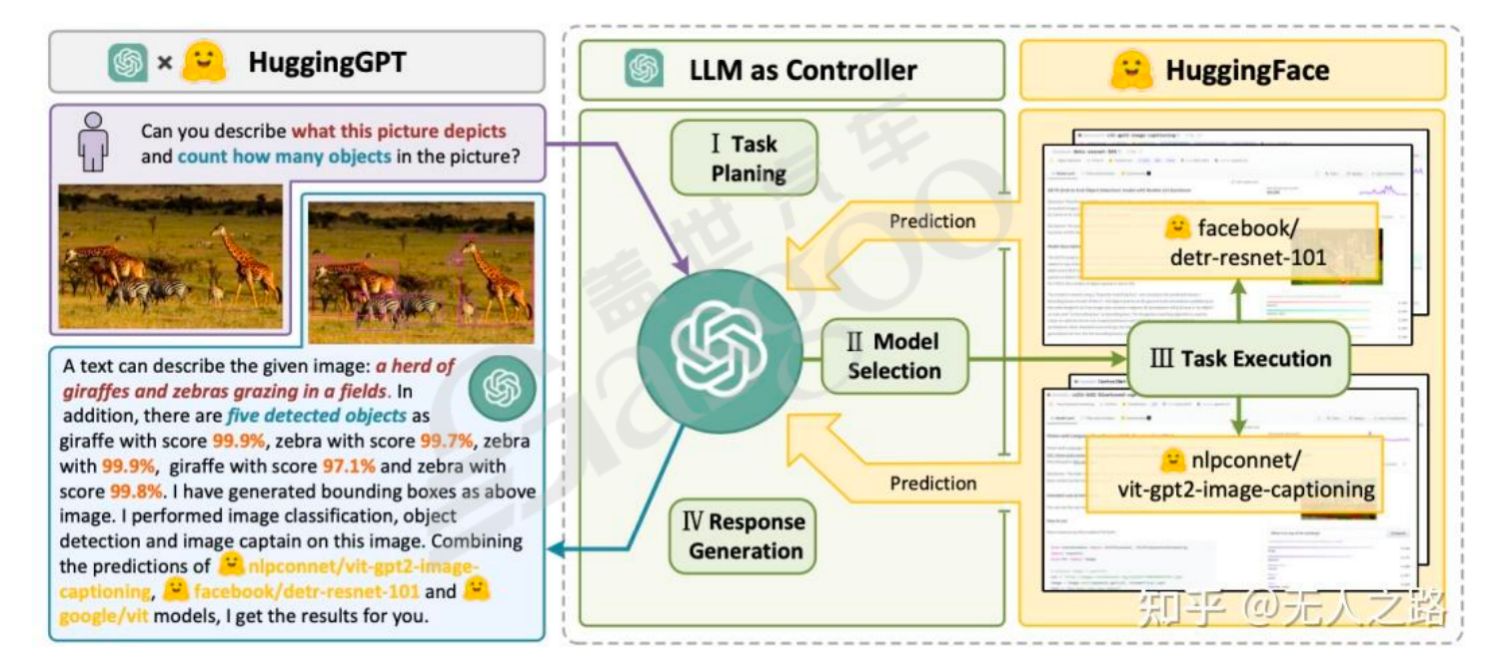
在多模态应用领域,以Hugging GPT为例,它将LLM作为控制器,结合Hugging Face社区的模型,把用户任务分解为任务规划、模型选取、任务执行和响应生成四个步骤,实现了强化语言调用多模态工具以完成具体业务。多模态应用还包括与物理世界和其他外围知识融合,创造新奇的实体产品,如自动驾驶的仿真生成。在生成类应用中,存在不同的类型,OpenAI的Sora性质的应用属于AIGC范畴,通过语言形式生成模型;而谷歌的特斯拉自动驾驶相关应用则是根据历史信息生成未来信息,二者在本质上存在差异。
在自动驾驶领域,其发展经历了多个重要阶段。传统的自动驾驶系统具有人工标注、单张图片标注、分立模型结构以及依赖规则算法和工程师经验等特点。随着技术的发展,时序模型被引入,数据采集方式从单张图片采集转变为持续性采集,实现了融合预测一体化,BEV类模型开始出现,众包地图技术参与云端训练,地图类数据接入实车系统,差分采集回收数据机制成为标配。BEV模型将传感器数据直接转换为俯视图表示,能够更有效地完成坐标系转换,提升车辆的感知维度。同时,存在体素和矢量两种不同的表征方式,它们在处理不同类型问题时各有优劣,相互配合,但在端到端模型中,为了提高对cornercase的处理能力,放弃了对一些信息的明文表达。目前,自动驾驶的主流方案是感知融合预测一体化并实现规控的数据驱动化,整个程序基本实现模型化,但尚未达到端到端的水平。在这个过程中,仍面临着如对特定场景(如水塘、交警等情况)的处理能力受限、模型能力上限被约束等问题。此外,还有像不可见地图预测等技术的探索,旨在降低地图成本并提高决策的准确性。
自治类GPT与工具调用技术在不断发展的过程中展现出巨大的潜力,但也面临着诸多挑战。无论是在技术的完善、工程化的实现,还是在与实际应用场景的深度融合方面,都需要持续的研究与探索,以推动这一领域朝着更加成熟、实用的方向发展。
网友评论