音频基础知识-中|盖世大学堂智能座舱系列知识讲解
一、音频采集
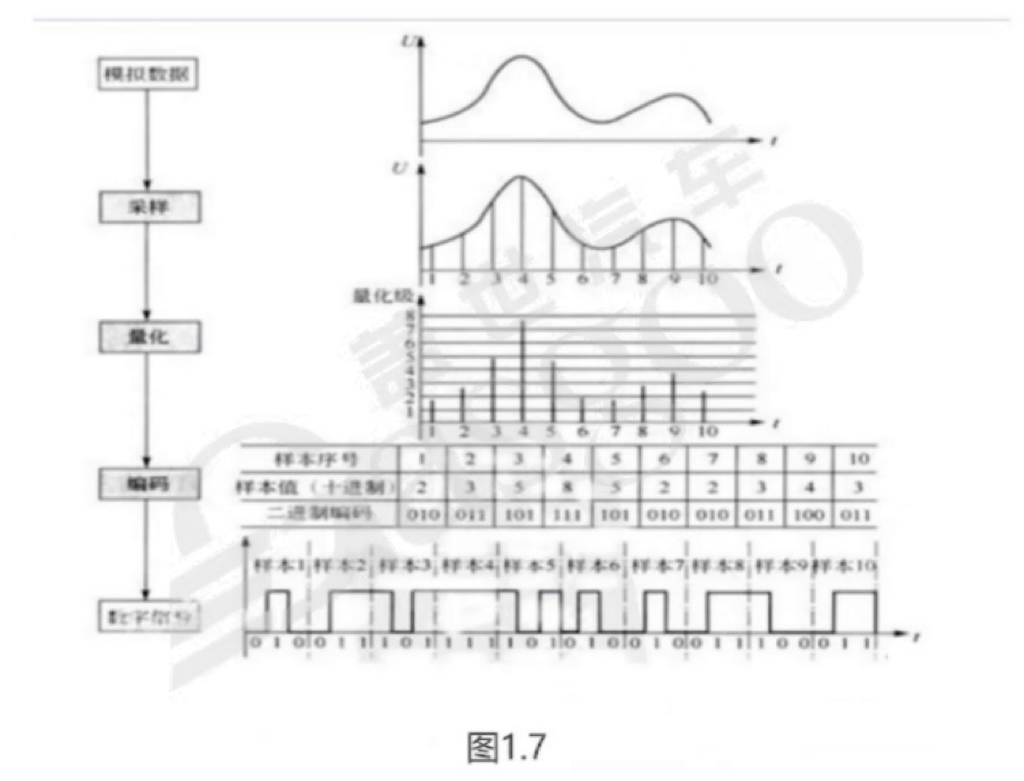
音频采集是将连续的模拟音频信号转换为离散数字信号的过程,以便在计算机系统中进行传输和存储。其核心步骤包括采样、量化和编码。
1.采样:采样是按照特定时间间隔在连续的音频波上进行取值的操作,由采样器完成。采样器在不同信号处理场景下,既可以是一个子系统,也可以指一个操作过程或算法。理想的采样器应尽可能避免信号失真。由于人耳可听频率范围大约在20Hz到20000Hz之间,因此在采样前端通常会设置滤波器电路,用于滤除小于20Hz或大于20kHz的杂波信号。这些杂波信号既无法被人耳感知,又会占用存储空间,所以需要去除。
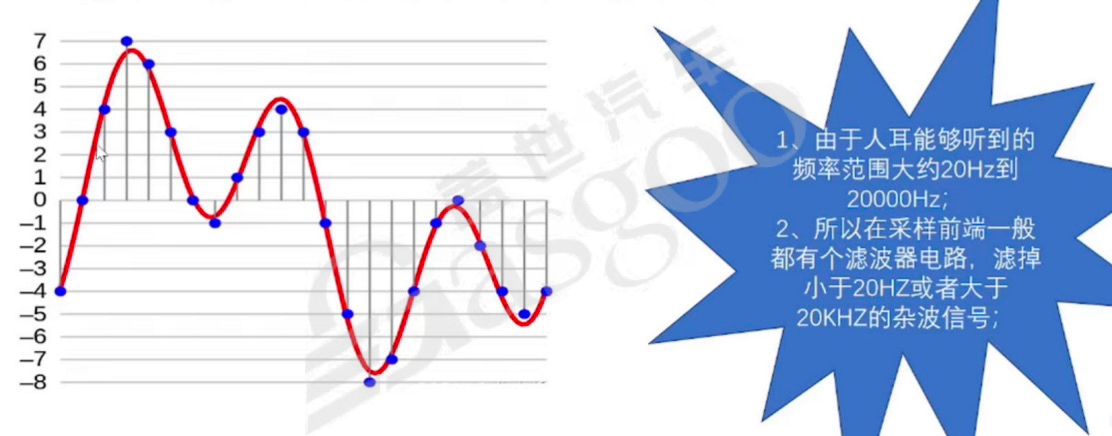
根据奈奎斯特采样定理,对于带限信号进行离散采样时,采样频率必须高于其最高频率的2倍(即一个周期内至少采2个点),才能从采样信号中唯一正确地恢复原始带限信号。最高频率的2倍被称为奈奎斯特频率。若采样频率不满足此条件,则无法准确恢复原始信号。常见的音频采样频率及其主要用途如下:电话机采样为11kHz;FM无线电采样为22kHz;CD标准采样为44.1kHz;HD高清音频规格采样为48kHz;Full HD音频规格采样为96kHz;Super HD音频规格采样为192kHz。未来的音频载体将倾向于HD标准。
2. 量化:采样后的值需进行量化处理,即将连续值近似为某个范围内有限多个离散值。由于原始音频数据是模拟的连续信号,而数字信号表达范围有限且具有离散性,因此量化是音频数字化过程中不可或缺的环节。量化过程可类比为给纵坐标设定刻度,并记录每个采样点的纵坐标值。
3. 编码:在计算机系统中,所有数值均以二进制形式表示。因此,需要将量化值进行二进制编码,将每个量化后的样本值转换为二进制代码。这一步骤通常与量化同时进行。完成编码后,将所有样本的二进制编码连接起来存储在计算机上,便形成了音频文件,即声音的数字信号。
脉冲编码调制(PCM)是将模拟信号数字化的经典方式,在计算机、DVD以及数字电话等系统中得到广泛应用。其基本原理是对原始模拟信号依次进行抽样、量化和编码,从而产生PCM流。
二、音频采集中的概念
1. 采样深度:采样深度指的是一个采样值用多少个bit存放,常用的采样深度有16bit(这意味着在量化过程中,纵坐标的取值范围是0 - 65535)。采样深度对音频采样的准确性具有重要影响,因为量化时取值范围的宽度以及可用离散值的数量,会直接决定音频采样能否精确反映原始音频信号。
2. 采样率:采样率即采样频率,指的是1秒内的采样次数。在将连续信号转换为离散信号时,采样周期的选择至关重要。若采样周期过长,虽然可以控制文件大小,但采样后得到的信息可能无法准确表达原始信息;反之,若采样频率过快,最终产生的数据量会大幅增加。这两种情况都不理想,因此需要根据实际应用场景选择合适的采样速率。一般来说,采样频率越高,音频波形的失真度越低,但存储数据量也越大;采样精度(采样电压位数)越高,波形失真度同样越低,存储数据量也会相应增加。例如,在播放音乐场景中,48kHz的采样率通常已能满足需求,而高通平台在音频处理中大部分采用24比特的采样深度。

3. 声道数:一个声道代表一种独立的音频信号。为了在播放声音时还原真实的声场,录制声音时会在前后左右等不同方位同时获取声音,每个方位的声音即为一个声道。声道数是指声音录制时的音源数量或回放时相应的扬声器数量,常见的有声道类型包括单声道、双声道和多声道。
单声道早期应用于音频录制,它仅记录一种音源,处理相对简单。播放时理论上使用一个扬声器即可,即便配备多个扬声器,由于信号源相同,也难以呈现出丰富的音效。立体声能够让人们感受到声音的空间感,这是因为大自然中的声音本身具有立体特性。例如,当音源发声后,音频信号会先后到达人类的双耳,且到达双耳的时间和强度存在细微差异,大脑通过处理这些差异来判断声源的方位。在音乐会录制中,若采用单声道采集,后期回放时所有音乐器材的声音会从一个点发出;而采用立体声录制并模拟现场场景播放时,则能营造出逼真的音乐会氛围。
常见的多声道系统有4.1、5.1、7.1.4等。以7.1.4声道为例,“7”表示在不同方位分布的7个声道,用于还原不同位置的声音;“1”代表专门用于重低音的声道,连接重低音喇叭;“4”表示车顶上的4个顶棚喇叭声道。这些多声道系统通过在不同位置布置扬声器,能够提供更加沉浸式的音频体验。
4. 音频帧:帧用于记录一个声音单元,其长度为样本长度(采样位数)和通道数的乘积。在音频处理中,帧表示一个完整的声音单元,即一个采样样本。例如,对于双声道音频,一个完整的声音单元包含2个样本;对于5.1声道音频,则包含6个样本。帧的大小(一个完整声音单元的数据量)等于声道数乘以采样深度,即frameSize = channelCount * bytesPerSample。在音频数据管理中,无论是框架层还是内核层,均以帧为单位管理音频数据缓冲区。最小缓冲区的大小等于最低帧数乘以声道数乘以采样深度。若数据缓冲区分配过小,会导致声音断续卡顿,严重影响听觉体验。
三、Nyquist - Shannon采样定律
在音频采样过程中,Nyquist - Shannon采样定律发挥着关键作用。该定律的核心思想是:当对被采样的模拟信号进行还原时,其最高频率只有采样频率的一半。这意味着,若要完整重构原始的模拟信号,采样频率必须是其最高频率的两倍以上。采样频率越高,声音还原效果越真实、自然,但同时数据量也会越大。鉴于人耳所能辨识的声音频率范围在20 - 20kHz之间,人们通常选用44.1kHz(CD标准)、48kHz或96kHz作为采样速率。以人声采样为例,44.1kHz的采样频率应用较为广泛,这是因为若采样频率数值过小,声音会产生失真现象;而在当前应用环境下,采样频率数值过大也无法显著提升人耳所能感知的音质。
四、车载麦克风相关知识
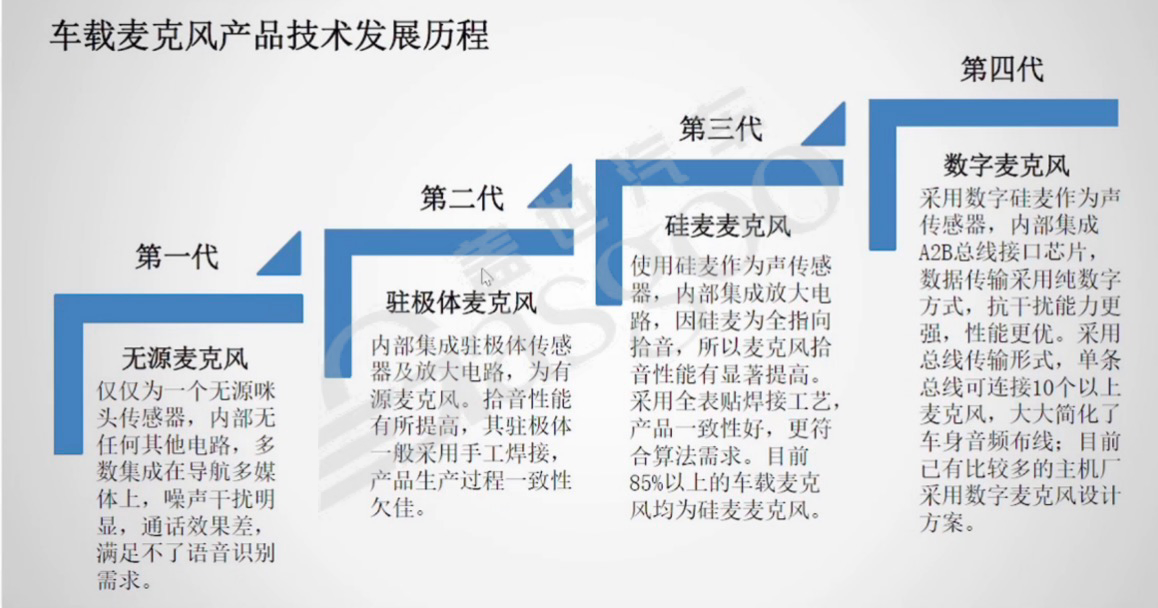
1.车载麦克风产品技术发展历程:车载麦克风技术经历了多个发展阶段。第一代驻极体麦克风,内部集成驻极体传感器及放大电路,为有源麦克风,多采用手工焊接,多数集成在导航多媒体上,噪声干扰明显,通话效果差,无法满足语音识别需求。第二代硅麦麦克风,使用硅麦作为声传感器,内部集成放大电路,因硅麦为全指向拾音,麦克风拾音性能有所提高,但产品生产过程一致性欠佳。第三代数字麦克风,采用数字硅麦作为声传感器,内部集成A2B总线接口芯片,数据传输采用纯数字方式,抗干扰能力更强,性能更优。采用全表贴焊接工艺,产品一致性好,更符合算法需求。目前,85%以上的车载麦克风为硅麦麦克风,已有较多主机厂采用数字麦克风设计方案。2.数字麦克风与模拟麦克风对比:与模拟麦克风相比,数字麦克风具有诸多优势。在传输线束要求方面,数字麦克风要求较低,仅需双绞线即可;而模拟麦克风要求较高,需要使用屏蔽双绞线。抗干扰性上,数字麦克风强于模拟麦克风。组网能力方面,数字麦克风方便组网,模拟麦克风则较差。在对手件接口需求上,数字麦克风无需其他输入口,可根据A2B总线获得数据;模拟麦克风则需增加多路接口。频响范围和主动降噪表现上,数字麦克风频响范围大,有更优秀的主动降噪效果;模拟麦克风频响范围小,主动降噪有限。此外,数字麦克风体积小,适合表面贴装技术(SMT);模拟麦克风体积大,不适合SMT。
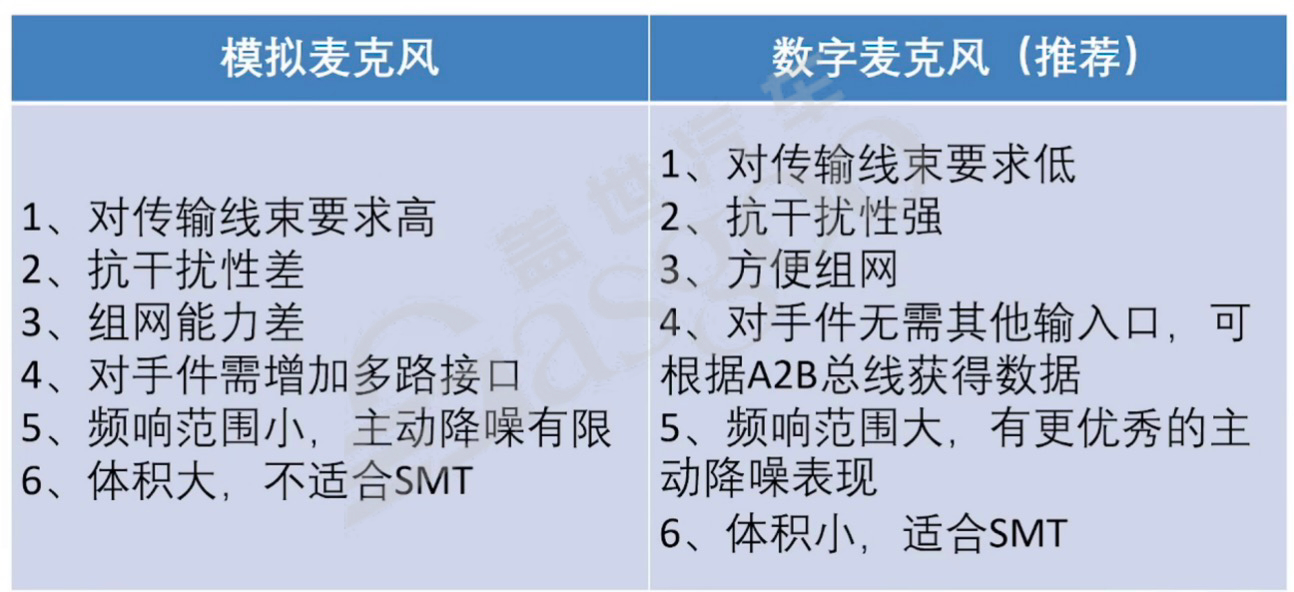
2.数字麦克风与模拟麦克风对比:与模拟麦克风相比,数字麦克风具有诸多优势。在传输线束要求方面,数字麦克风要求较低,仅需双绞线即可;而模拟麦克风要求较高,需要使用屏蔽双绞线。抗干扰性上,数字麦克风强于模拟麦克风。组网能力方面,数字麦克风方便组网,模拟麦克风则较差。在对手件接口需求上,数字麦克风无需其他输入口,可根据A2B总线获得数据;模拟麦克风则需增加多路接口。频响范围和主动降噪表现上,数字麦克风频响范围大,有更优秀的主动降噪效果;模拟麦克风频响范围小,主动降噪有限。此外,数字麦克风体积小,适合表面贴装技术(SMT);模拟麦克风体积大,不适合SMT。
3.麦克风主要参数:麦克风的主要性能参数包括灵敏度、频响范围、失真度、输出阻抗、信噪比、最大声压、工作电流、频响偏差、工作电压、麦克类型、声传感器、指向性、通信方式、通信速度、传输方式、布线难度、主动降噪能力、故障诊断能力等。不同类型的麦克风在这些参数上存在差异,例如A2B数字麦克风和模拟麦克风在各项参数上均有不同表现,这些参数在麦克风选型过程中起着重要作用。
五、音频的压缩与存储
1. 音频压缩:处理后的RAW音频数据体积通常较大,不利于保存和传输,因此通常需要对其进行压缩处理。例如常见的mp3音乐,就是对原始音频数据采用相应压缩算法后得到的。压缩过程会根据采样率、位深等因素的不同,使最终得到的音频文件产生一定程度的失真。音视频的编解码既可以通过纯软件实现,也可以借助专门的硬件芯片完成。
音频压缩主要分为不压缩、无损压缩和有损压缩三种类型。不压缩的音频格式如WAV、AIFF,其中WAV是由微软和IBM联合开发的用于音频数字存储的标准,可直接存储未经压缩的PCM数据,在Windows系统上通常以wav后缀存储;AIFF常用于Mac系统。无损压缩格式包括FLAC、APE(Monkey's Audio)、WV(WavPack)、m4a(Apple Lossless)等,这类压缩方式在不破坏音频信息的前提下,能够一定程度减小文件体积,后期可完整还原原始数据。有损压缩格式中最为人熟知的是mp3,以及iTunes上使用的AAC。这些格式可以指定压缩比率,比率越大,文件体积越小,但音质效果也会相应变差。
音频压缩的基本原理基于频谱掩蔽效应和时域掩蔽效应。频谱掩蔽效应是指人耳所能察觉的声音信号频率范围为20Hz - 20kHz,超出此范围的音频信号属于冗余信号,在压缩过程中可被去除。时域掩蔽效应是指当强音信号和弱音信号同时出现时,弱信号会被人耳忽略,因此弱音信号也被视为冗余信号,可通过相应算法在压缩过程中去除。
2. 音频存储:在音频处理过程中,需要注意文件格式和文件编码器的区别。编码器负责对原始数据进行前期处理,如采用压缩算法减小体积,然后将处理后的数据以特定文件格式保存。文件格式和编码器并非一一对应关系,例如常见的AVI格式就支持多种音频和视频编码方式。模拟音频信号转换为数字信号后,经过采样、量化和编码产生的PCM数据,添加文件头信息后可存储为WAV文件,该文件格式易于解析和播放。
六、音频回放
1. 音频回放流程:音频回放从逻辑上可视为音频采集的逆过程,其实际流程是从本地存储取出音频相关文件,或从网络端获取实时音频流,然后根据录制过程采用的编码方式进行相应解码。接着,智能设备的音频系统为该播放实例选定最终匹配的音频回放设备。解码后的数据经过音频系统设计的路径传输,再通过数模转换器(DAC)将音频数据信号变换成模拟信号,最后模拟信号经过回放设备还原出原始声音。
2. 音频回放的概念:音频回放过程涉及到与音频采集相同的概念,如采样深度、采样率、声道等。与音频采集不同的是,音频回放需要根据用户实际情况控制回放声音的大小,以满足用户的个性化需求。
网友评论